
音素到倒频谱映射
递归神经网络
框架
§基于 HMM 的蒙古语语音合成方法
§参数法:基于深度神经网络的蒙古语语音合成方法
§端到端语音合成
基于情感的语音合成
straight
语音合成参数选择
特征参数选择:提取语音信号的频谱参数作为模型的特征参数(观测值)
语音识别和说话人识别:Mel域倒谱系数(MelFrequency Cepstral Coefficiem,,MFCC)参数,倒谱(Cepstrum)和Mel域倒谱(Mel.Cepstnun)
情感语音合成
语音合成:最初的物理机理语音合成,波形拼接语音合成,韵律转换语音合成到统计参数语音合成和深度学习语音合成
情感语音合成:波形拼接合成方法,韵律特征修改方法和基于隐马尔可夫模型( hidden Markov model, HMM )的统计参数语音合成方法
HMM
传统参数语音合成方法是基于统计学习和决策树的隐马尔科夫-高斯混合模型 (HMM)。HMM 对声音特征的适应性和鲁棒性高、需要较小的计算代价和在 训练数据较少的时候有更好的表现[3]等诸多优点,使其 长期成为语音合成方法的主流技术。
§但是合成的质量不高,主要的原因是由于其生成的过程是离散的
LSTM神经网络
神经网络是更为广泛的数值型计算模式,前向网络模型建立样本到标签的一对一映射,循环神经网络(RNN)在序列间建立映射,全部计算均为连续数值空间,没有HMM离散规则跳转。长短期记忆神经网络 (LSTM)克服了普通循环神经网络梯度消散或爆炸问题。
语音合成模型
音素到倒频谱映射
文本音素信息到倒频谱之间的映射关系是语音合成系统的核心部分。神经网络一次输入对应一次输出,需要训练两个模型:1.音素时长模型,倒频谱模型。
§音素因袭是包含发音与语言相关的向量序列。预测时长后使用时长扩展音素信息为多个描述帧,对应预测倒谱郑时长模型决定韵律,倒频谱决定音色和音调,两这对合成质量有决定性作用
§音素信息序列和帧序列都是一系列配对向量。使 用深度神经网络和循环神经网络都可以对输入和输出 进行映射。
递归神经网络
当前输出会受上一次前馈计算的影响,而当前输出后的 网络状态又继续影响下一次输出。
§ht是网络当前状态,由上一状态ht-1、当前输入xt 和激活函数f共同影响。
§LSTM 包含输入门(IG)、遗忘门(FG)和输出门 (OG)将状态传递变为累加。输入门控制新状态(NI)加 到当前状态中的比例,遗忘门决定保留多少旧状态,输出门将状态映射到最终输出。三个门限各自有的功能,不能简单地去掉。
语音合成主要流程
框架
主要分为前端处理和后端处理:前端处理主要是根据先验知识对文本进行语言及语法层面的分析。对于后端合成部分,主要是对波形拼接和参数合成。
波形拼接方法是根据文本分析从语料库中选取相应的语音单元片段,然后进行单元片段的拼接完成语音合成。参数合成方法是从数字信号处理,统计学等角度,对声 码器提取的声学特征参数进行统计建模,然后把模型预测得到的声学特征参数输入声码器完 成语音合成。
主流的框架有:百度的Deepvoice Google的tacotron 和Tacotron2, wavenet(直接对语音参数和波形之间进行建模,弥补传统声码器损失语音细节信息的缺陷。
基于 HMM 的蒙古语语音合成方法
基于 HMM 的蒙古语语音合成方法主要包括以下流程:前端处理、模型训练和后端合成。 前端处理部分主要是文本处理,输入的文本经过特殊字符转换、拉丁校正、字母转音素、上 下文标注转换为对应的语言特征。对于模型训练部分,选取谱特征和激励特征及其动态特性 作为声学特征,训练流程如下:首先进行单音素 HMM 模型的初始化及训练,并使用预先设 计的问题集进行上下文(三音素)决策聚类,然后使用训练得到的单音素 HMM 模型参数初始 化决策聚类后的上下文 HMM 模型,最后进行上下文 HMM 模型及时长 HMM 模型的训练。 对于后端合成部分,输入的蒙古语文本经过前端处理得到相应的语言特征,根据训练得到的 上下文 HMM 模型及时长 HMM 模型,预测声学参数及持续时长,然后使用声码器完成语音 的合成。
HMM的声学特征的建模:谱特征MGC和激励特征logF0作为声学特征。
Mel域倒谱特征或者线谱对特征,和提取了浊音段的基频参数描述语音中的激励。
建模单元:一般是以音素作为建模单元,中文是对声韵母建模。
HMM拓扑结构:HMM一般采用由左向右并且各态历经的拓扑结构。
§


QynJfB47CrkwOZs
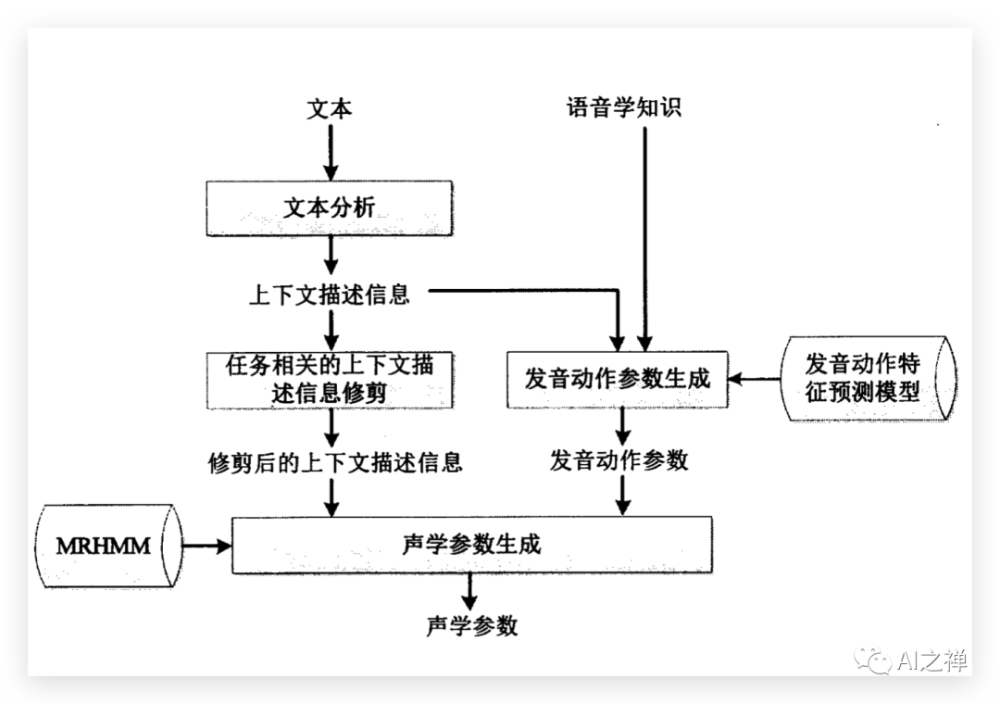
参数法:基于深度神经网络的蒙古语语音合成方法
运用深度神经网络进行声学特征参数的预测是该方法的核心,该方法同样有三个部分组 成,前端处理,模型训练,后端合成。对于前端处理部分,与基于 HMM 的蒙古语语音合成 方法的前端处理类似,其作用是把输入的蒙古语文本转换为对应的语言特征。模型训练部分, 采用谱特征、激励特征、频带周期特征及其动态特性作为声学特征。模型包括基于 HMM 的 时长模型和基于 DNN 的声学模型,时长模型训练与基于 HMM 的蒙古语语音合成方法中时 长模型训练流程相同。对于声学模型训练,使用 DNN 对语言特征与声学特征之间的映射关系 进行建模。对于后端合成,输入文本经过前端处理,得到相应的语言特征,然后根据 HMM 时 长模型和 DNN 声学模型分别预测持续时长和声学特征参数,最后使用声码器重构语音波形。
端到端语音合成
语音合成方法主 要分为三个部分,其一,前端处理部分,主要包括特殊字符转换,拉丁校对。其二,预测梅 尔频谱模型部分,该部分采用梅尔频谱作为中间特征,模型部分采用带有注意力机制的编码器-解码器模型结构。最后是梅尔频谱转换语音波形部分,该部分首先使用了梅尔频谱预测频 谱幅度模型即带有多层高速公路网络和双向门控循环单元的卷积单元(Convolutional Bank with Highway networks and Grated recurrent unit, CBHG) 模块把梅尔频谱转换为频谱幅度(目 标特征),然后根据得到的频谱幅度使用 Griffin-Lim 算法进行相位预测,重构语音波形。
前端处理流程
§Hr29y8QibkM5ZlJ
§前端处理、预测梅尔频谱 模型、梅尔频谱转换语音波形模块。蒙古语文本经过前端处理得到对应的拉丁字符序列,然 后字符序列输入到预测梅尔频谱模型得到对应的梅尔频谱,最后梅尔频谱经过梅尔频谱转换 语音波形模块进行蒙古语语音的合成。
§端到端语音合成主要包括两个模型:预测梅尔频谱模型和梅尔频谱预测频谱幅度模型,梅尔频谱作为中间转换特征,频谱幅度作为目标特征。
§选择梅尔频谱作为主要的声学特征参数,由于梅尔频谱对短时傅里叶变换的频率轴做一个非线性变换,用较少的维度对频率范围进行压缩变换得到,比波形样本更具有平滑。
wavenet 声码器
wavenet是一种自回归的深度生成模型,该模型可以直接在原始音频层面上进行建模,具有全概率和自回归性,每个音频样本点的预测分布取决于之前的所有音频样本点,对于音频样本x=x1,...xt的联合概率被分解为条件概率的乘积。
§WaveNet 结构优于 PixelCNNs 结构最突出的特点是采用扩展因果卷积,使用因果卷积可以保证建模时不会违反样本点的先后顺序,预测 p(xt+1,x1,...,xt)使用的是样本点xt+1之前的序列信息,而不使用xt+1,xt+2,...,xT 等未来样本点的信息。
基于情感的语音合成
基于HMM的语音合成
DNN情感语音合成
§基频( fundamental frequency ,F0)、谱参数(MGC, BAP)和浊音/清音(voice/unvoiced,V/UV)
语音分析合成算法
straight
STRAIGHT是一种针对语音信号的分析合成算法,经过其分析合成后的语 音可以保留较高质量,并且可以利用该算法可以对语音的时长、基频和频谱参数进行调整。
§去除周期影响的谱估计
§在分析语音信号时,我们首先对语音信号进行加 窗处理,研究其短时谱。因此语音信号的短时谱在时域及频域上表现出和 基音周期相关的周期性。利用STRAIGHT语音分析合成算法可以分别去;
§可靠的基频提取:
§STRAIGHT语音分析合成算法通过对频谱进行谐波分析 得到浊音段的基频参数,该算法提取的基频轨迹更为精确和稳定;
§合成器的实现:
§STRAIGHT进行合成时采用基于基音同步叠加和最小相位 冲激响应的方法,并且可以在合成过程中对时长、基频和谱参数进行灵活 地调整。








