
随着人工智能(AI)技术的不断发展,越来越多的研究者开始关注AI技术在医学健康领域的研究应用,其中加速AI技术发展的一个关键环节是标准数据集和科学评估体系的建立。
由中国中文信息学会医疗健康与生物信息处理专业委员发起的中文医疗信息处理挑战榜CBLUE[1]于今年4月份上线,该 benchmark 覆盖了8类经典的医学自然语言理解任务,是业界首个公开的中文医疗信息领域公开评测基准。
CBLUE上线后受到了产研界的广泛关注,目前已经吸引了300多支队伍参与打榜。近日,CBLUE工作组公开了论文[2]并开源了评测基准baseline[3]。本文对常见的医学自然语言理解任务以及模型方法做一个全面介绍。
任务介绍
CBLUE的全称是Chinese Biomedical Language Understanding Evaluation Benchmark,包括医学文本信息抽娶医学术语标准化、医学文本分类和医学问答4大类经典的医疗信息处理任务。
CBLUE为研究者们提供真实场景数据的同时,也为多个任务提供了统一的测评方式,目的是促进研究者们更加关注AI模型的泛化能力。
以下是各个子任务的简单介绍:
(1)医学信息抽取
CMeEE(Chinese Medical Entity Extraction dataset):医学实体识别任务,识别出医学文本中的关键术语,如“疾病”、“药品”、“检查检验”等。
CMeIE(Chinese Medical Information Extraction dataset):医学关系抽取任务,即推断医学文本中两个实体之间的关系,如“类风湿性关节炎”与“关节压痛计数” 两个医学术语之间构成了“疾病-检查”的关系。实体识别和关系抽取是医学自然语言处理中非常基础的技术,可应用于电子病历结构化、医院数据治理、医学知识图谱建设等应用场景。
(2)医学术语归一化
CHIP-CDN(CHIP - Clinical Diagnosis Normalization dataset):医学临床术语标准化任务。临床上,关于同一种诊断、手术、药品、检查、症状等往往会有成百上千种不同的写法(如:“Ⅱ型糖尿病”、“糖尿病(2型)”和“2型糖尿病”均表示同一个概念), 标准化要解决的问题就是为临床上各种不同的写法找到对应的标准术语(如“ICD编码”)。在真实应用中,术语标准化技术在医保结算、DRGs(诊断自动分组)等应用场景中发挥着重要作用。
(3)医学文本分类
CHIP-CTC(CHIP - Clinical Trial Criterion dataset):临床试验筛选标准分类任务。临床试验是指通过人体志愿者也称为受试者进行的科学研究,目的是确定一种药物或一项治疗方法的疗效、安全性以及存在的副作用,对促进医学发展和提高人类健康都起着关键的作用。筛选标准是指临床试验负责人拟定的鉴定受试者是否满足某项临床试验的主要指标(如“年龄”、“血型”等),临床试验的受试者招募一般是通过人工比较病历记录表和临床试验筛选标准完成,这种方式费时费力且效率低下。本数据集推出的目的就是为了促进使用AI技术来自动做临床试验筛选分类,提升科研效率。
KUAKE-QIC(KUAKE - Query Intention Classification dataset):医疗搜索用户查询意图识别任务,目标是为了提高搜索结果相关度,更好的服务于互联网用户。如用户查询“糖尿病该做什么检查?”的意图是想搜索相关的“治疗方案”。
(4)医学检索和问答
CHIP-STS(CHIP - Semantic Textual Similarity dataset):医学句子语义匹配任务。给定来自不同病种的问句对,判定两个句子语义是否相近,如“糖尿病吃什么?”和“糖尿病的食谱?”是语义相关的;“乙肝小三阳的危害”和“乙肝大三阳的危害”是语义不相关的。
KUAKE-QTR(KUAKE Query/Title Relevance dataset):医学搜索“检索词-页面标题”相关度匹配任务,用于判定搜索引擎场景中用户检索词与返回页面的标题之间的相关度,目标是提升搜索结果的相关度。
KUAKE-QQR(KUAKE Query/Query Relevance dataset):医学搜索“检索词-检索词”相关度匹配任务,同QTR任务,用于判定两个检索词之间的语义相关度,目标是提升搜索场景中经典的用户检索长尾词的召回率。
任务特点
CBLUE工作组对评测基准包含的8个任务做了特点总结:
数据匿名且保护隐私
生物医学数据通常包含敏感信息,因此对这些数据的利用可能侵犯个人隐私。对此,我们在发布基准之前对数据进行不影响数据有效性的匿名化,并对每条开放的数据进行了人工检查以确保不涉及患者隐私。
任务数据来源丰富
如“医学信息抽取”大类的任务来源于专家权威指南;“医学文本分类”任务来源于真实开放的临床试验数据;“医学问答”类任务来源于搜索引擎或者互联网在线问诊语料。这些丰富的场景和数据多样性为科研人员提供了研究AI算法最重要的宝矿,同时也对AI算法模型的通用性提出了更高的挑战。
任务分布真实
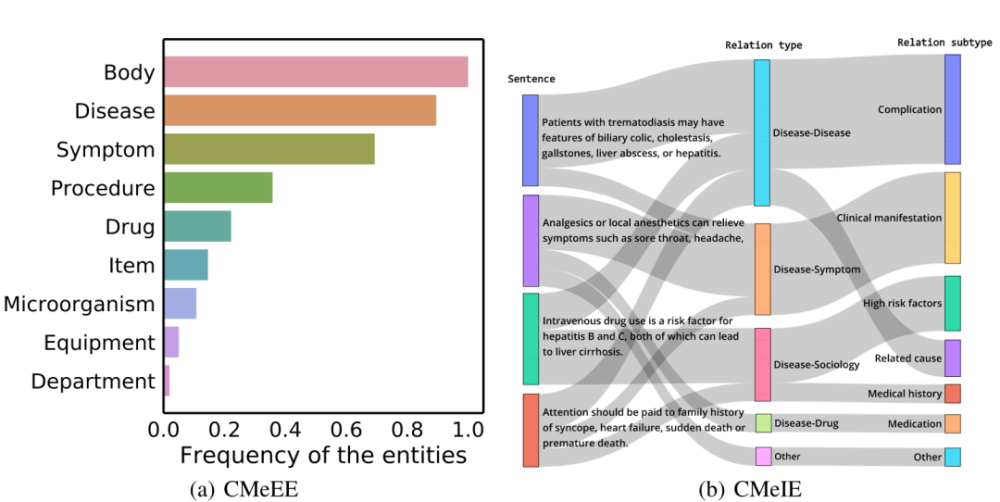
CBLUE榜单中的所有数据都来自现实世界,数据真实且有噪音,因此对模型的鲁棒性提出了更高的要求。以“医学信息抽取”大类任务为例:数据集遵循长尾分布,如图(a)所示;此外,一些数据集(如CMeIE)具有粗粒度和细粒度关系标签的层次结构,这是符合医学常识逻辑和人类认知的,如图(b)所示。真实世界数据分布为AI模型的泛化能力和拓展性提出了更高的要求。
方法介绍
以Bert[4]为代表,大规模预训练语言模型已经成为了NLP问题求解的新范式,因此CBLUE工作组也选择了11种最常见的中文预训练语言模型作为baseline来进行充分的实验,并对数据集性能进行了详尽的评估,目前是业界最全的中文医疗自然语言理解任务基线,可以帮助从业人员解决常见的医学自然语言理解问题。
11种实验的预训练语言模型简介如下:
BERT-base[4]
具有12层,768维表示,12个注意力头,总计110M参数的BERT基准模型;
BERT-wwm-ext-base[5]
使用全词遮蔽(Whole Word Masking,WWM)的中文预训练BERT基准模型;
RoBERTa-large[6]
与BERT相比,RoBERTa去除了下句预测(Next Sentence Prediction,NSP)任务,并动态选择对训练数据的遮蔽方式;
RoBERTa-wwm-ext-base/large
综合RoBERTa和BERT-wwm优势的预训练模型;
ALBERT-tiny/xxlarge[7]
ALBERT是在transformer的不同层共享权重,针对两个目标任务:遮蔽语言建模(Masked Language Model,MLM)和句子排序预测(Sentence Order Prediction,SOP)进行预训练的模型;
ZEN[8]
基于BERT的n-gram增强中文文本编码器;
Mac-BERT-base/large[9]
Mac-BERT是一种改进的BERT,采用MLM作为校正预训练任务,减少了预训练和微调阶段的差异;
PCL-MedBERT[10]
由鹏程实验室智能医学研究小组提出的一种医学预训练语言模型,在医学问题匹配和命名实体识别方面具有优异的性能。
性能评估&分析
下图为11种预训练模型在CBLUE上的基线表现:

如上表所示,使用更大的预训练语言模型,可以获得更好的性能。在某些任务中,使用全词遮蔽的模型并不比其他模型表现好,例如CTC、QIC、QTR和QQR,这表明CBLUE中的任务具有一定的挑战性,需要更好的模型来解决。
此外,我们发现albert-tiny在CDN、STS、QTR和QQR的任务中实现了与基础模型相当的性能,说明较小的模型在特定的任务中也可能是有效的。
最后,我们注意到医学预训练语言模型PCL-MedBERT的性能不如预期的好,这进一步证明了CBLUE的难度,当前的模型可能很难快速取得出色的效果。
结束语
CBLUE挑战榜的目标是可以让研究人员在合法、开放、共享的理念下有效的使用真实场景的数据,通过多任务场景设置来让研究者们更加关注模型的泛化性能。同时也希望公开的基线评测代码能有效的促进医疗AI社区的技术进步。








