
近日,阿里云人工智能平台PAI的论文《Llumnix: Dynamic Scheduling for Large Language Model Serving》被OSDI '24录用。论文通过对大语言模型(LLM)推理请求的动态调度,大幅提升了推理服务质量和性价比。
Llumnix是业界首个能灵活在不同模型实例间重新分配请求的框架;并且,实验表明,与最先进的LLM服务系统相比,Llumnix请求尾延迟时间剧减超过10倍,将高优先级请求的速度提高了1.5倍,并在实现类似尾部延迟的同时,成本降低为原先的64%。

OSDI是操作系统及分布式系统领域的旗舰级会议,OSDI与其姊妹会议SOSP长期以来对系统领域发展起着深刻的推动作用,在学术和工业界均有巨大影响力。OSDI/SOSP上曾诞生了许多影响深远的论文和系统,如GFS、MapReduce、BigTable等经典的分布式系统,以及如TensorFlow、TVM、vLLM等在人工智能领域产生深远影响的系统。
此次入选意味着阿里云人工智能平台PAI在大模型推理方向达到了业界先进水平,获得了国际学者的认可,展现了中国机器学习系统技术创新在国际上的竞争力。
自ChatGPT这一颠覆性产品问世以来,生成式大语言模型(LLM)技术迎来了堪称日新月异的发展,短短一到两年时间我们已经见证了一系列大模型及产品的诞生和应用。LLM推理服务也因此成为LLM不断产品化进程中的关键技术支撑。然而LLM推理的请求及其执行呈现高度的差异性、动态性和不可预测性,这些特性给现今的推理服务系统带来了一系列挑战,大大限制了LLM推理服务的效率。
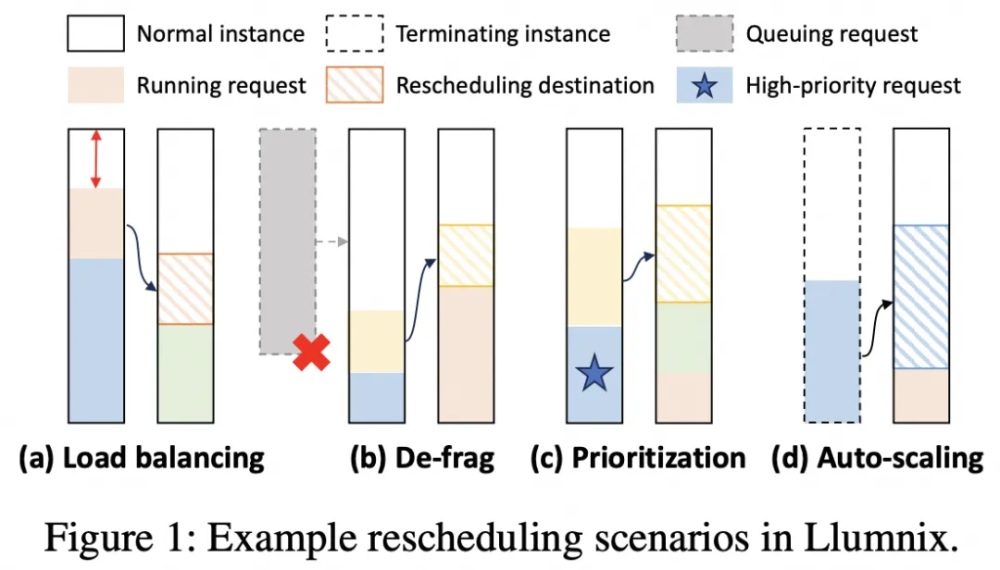
Llumnix是阿里云PAI团队研发的LLM推理动态调度框架,旨在利用调度的动态性来化解由请求的动态性带来的种种挑战。Llumnix是一个支持在多个模型实例之间对请求进行运行时重调度的框架,这一重调度能力使得Llumnix可以根据请求状态的动态变化对调度决策进行适应性调整,并以此实现了如负载均衡、碎片整理、请求优先级等一系列调度特性和优化(如下图)。通过在LLaMA系列模型上的实验,初步展示了动态调度的潜力,如大幅降低延迟,加速高优先级请求,以及降低服务成本等。
阿里云人工智能平台PAI团队对Llumnix进行了产品化研发,并已开源(Github地址:https://github.com/AlibabaPAI/llumnix)。当前版本的Llumnix支持vLLM为后端推理引擎,可自动化拉起多实例vLLM服务,并在多实例之间进行请求调度及重调度。Llumnix保持了与vLLM非常相似的用户接口,从而以尽可能平滑和透明的方式加持在已部署的vLLM服务之上。目前,开源版本的Llumnix处于alpha状态,仍在积极研发和迭代中。欢迎您的试用和反馈!后续Llumnix将与阿里云人工智能平台PAI自研的BladeLLM推理引擎、PAI-EAS模型在线服务等产品深度结合,形成一体化的高性能LLM推理套件,并集成进入PAI灵骏智算服务产品,助力企业和个人开发者完成云上大语言模型服务的创新。
论文信息
论文标题:Llumnix: Dynamic Scheduling for Large Language Model Serving
作者:孙彪,黄梓铭,赵汉宇,肖文聪,张欣怡,李永,,林伟
论文地址:https://www.usenix.org/conference/osdi24/presentation/sun-biao







