
Highlight
产品介绍
Hologres 是阿里云自研一站式实时数仓,统一数据平台架构,将OLAP查询、即席分析、在线服务、向量计算多个数据应用构建在统一存储之上,实现一份数据,多种计算场景。
V2.1 版本简介
新增弹性计算组实例,解决实时数仓场景下分析性能、资源隔离、高可用、弹性扩缩容等核心问题,同时新增多种用户分析函数与实时湖仓Paimon格式支持,COUNT DISTINCT优化显著提升查询效率。
升级说明:Hologres支持热升级,跨大版本升级建议停机升级。
弹性计算组(warehouse)构建高可用实时数仓
功能说明:
Hologres弹性计算组(warehouse)采用Shared Data 架构,存储共用一份,计算资源分解为不同的计算组(Warehouse),每个计算组可独立弹性扩展,计算组之间共享数据、元数据。
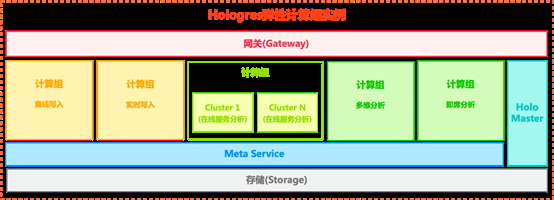
应用场景:
弹性计算组有多种使用方式,用户可以实现高可用、负载隔离与降本,并显著提升故障恢复速度及使用易用性。
● 隔离与高可用:计算组之间物理隔离,不同部门业务之间实现读读隔离、写写隔离、读写隔离,同时避免计算组之间的相互影响,减少业务抖动。
● 成本与弹性:存算分离,存储共享一份,计算组可动态热扩缩容,显著降低成本。
● 易用性:对应用只暴露一个Endpoint,新增与销毁、故障实例切换等操作通过简单SQL即可快速实现,实现故障自动路由。
其他核心能力
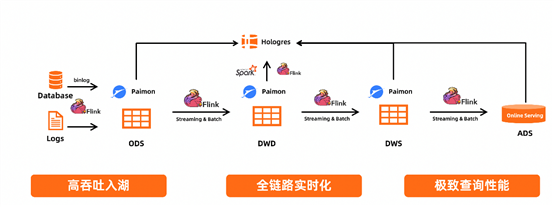
实时湖仓新增Paimon格式
功能说明:
Hologres实时湖仓能力在之前版本支持ORC、Parquet、CSV、SequenceFile、HUDI、Delta、Parquet等多种格式,V2.1 版本新增Paimmon格式,Apache Paimon是流批统一的湖存储格式,支持高吞吐的写入和低延迟的查询,促进数据在数据湖上真正实时的流动,并为用户提供基于湖存储的实时离线一体化的开发体验。
应用场景:
Flink +Paimon+ Hologres 实时湖仓。基于Flink将数仓以Paimon这种 Table Format 形式在湖上构建,上层可以使用 Flink进行流计算,使用 Hologres 对所有层次做统一的OLAP查询或者是最上面的ADS层做在线分析。方案中Paimon可以实现高吞吐的入湖,Flink 可以实现全链路的实时计算,Hologres 可以实现高性能的OLAP查询,所以整个链路从实时性、时效性、成本几个方面都可以取的比较好的平衡。
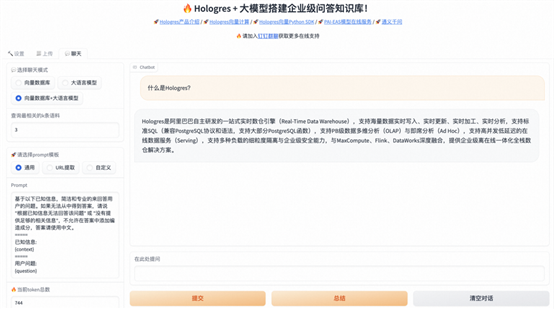
向量计算新增计算巢方案,5分钟拉起企业级知识库
功能说明:
基于计算巢能力,5分钟一键拉起Hologres向量计算+PAI部署大模型所需资源,直接通过WebUI与示例数据,进行大模型+向量计算对话。
应用场景:
企业级对话知识库构建。将专属行业知识向量化处理后,存储到向量引擎,通过向量计算结合大模型推理求解,输出专属领域准确答案,减少大模型问答幻觉,完成实时知识更新并提高问答速度。
自动优化CountDistinct,提升查询效率
功能说明:
Hologres从V2.1版本开始,针对Count Distinct场景做了非常多的性能优化(包括单个Count Distinct、多个Count Distinct、数据倾斜、SQL没有Group By字段等场景),无需手动改写成UNIQ,即可实现更好的性能。
应用场景:
在PV、UV计算等场景提升精确去重查询效率

对比V2.1与V2.0版本,V2.1在单条及多条Count Distinct的内存消耗、CPU使用、耗时上都有显著差异。

优化Runtime Filter能力,显著提升Join效率
功能说明:
Hologres V2.0版本支持1个join字段的Runtime Filter,V2.1开始支持多字段Join的Runtime Filter。在Join过程中,Hologres根据build端的数据特征和分布以及最终Join的数据量和原始扫描数据量,自动对probe端的数据进行裁剪,从而减少对probe端的数据扫描和Shuffler,以此来提升Join性能。
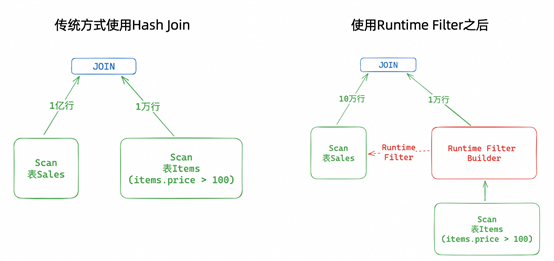
应用场景:
多字段join时,自动优化大小表join效率,如以下示例SQL,V2.1版本可以提升30%-100%查询速度。

Runtime Filter是自动触发的能力,无需手动开启。触发条件如下:
.probe端的数据量在100000行及以上。
.扫描的数据量比例:build端 / probe端 <= 0.1(比例越小,越容易触发Runtime Filter)。
.Join出的数据量比例:build端 / probe端 <= 0.1(比例越小,越容易触发Runtime Filter)。
新增漏斗、留存、路径等函数,简化用户行为分析
功能说明:
用户漏斗分析、留存分析、路径分析是常见的用户行为数据分析场景,Hologres新增漏斗、留存、路径函数,可以帮助用户更加简单、高效地完成行为分析。
应用场景:
用户漏斗分析,计算每个阶段行为转化率。Hologres原生支持漏斗函数,也支持区间漏斗函数,这样不仅可以看到每个阶段的漏斗结果,也可以分组展示漏斗的结果,不需要写额外的各种扩展语法。

用户留存分析,计算近3天、7天用户等留存。Hologres支持留存函数和留存扩展函数,方便业务可以高效的分析产品留存率,助力进一步业务决策。

用户路径分析,计算用户产品使用路径分布情况。Hologres路径函数可以基于事件,统计用户访问行为的流入留出,快速搭建用户路径桑基图。
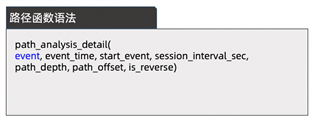
BSI+RB函数助力高效画像分析
功能说明:
Hologres原生支持Roaring Bitmap函数,将用户ID构建成Bitmap实现属性标签的快速分析;同时在2.1版本开始支持BSI函数,通过BSI的高效压缩和切片索引,实现行为标签的高效分析,同时在查询时可以通过二进制原理和Roaring Bitmap交并差运算进行快速计算,支持对高基数行为标签的压缩存储和低延迟查询,从而实现“属性标签”和“行为标签”的高效联动分析。
应用场景:
通过BSI函数+RB函数实现高效的行为分析与画像分析。例如在一张用户属性表,一张用户收入表,表结构如下:
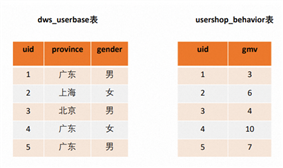
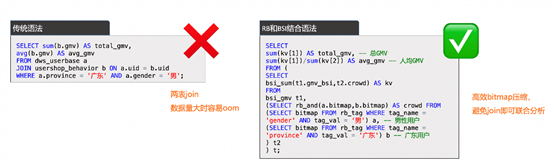
若要计算出“广东、男用户的GMV总和”,传统的Join语法,数据量大时容易OOM,通过高效bitmap压缩,避免join即可联合分析。
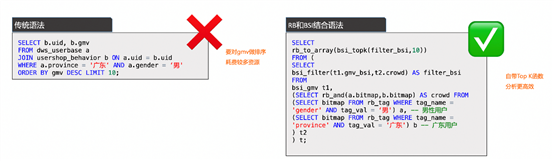
若要计算出“昨日广东男用户消费金额Top K”,传统语法对GMV排序要消耗大量资源,BSI+RB自带TopK函数,分析更高效。
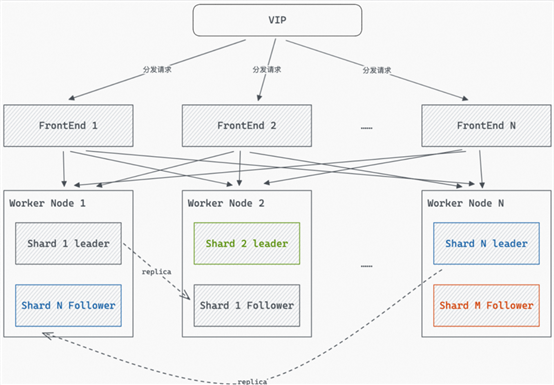
支持单实例Shard多副本,提升吞吐量,实现查询高可用
功能说明:
单实例Shard多副本是Hologres一直Beta中的能力,在V2.1版本正式发布,可以实现单实例内高可用及负载均衡扩吞吐场景,可容忍部分机器故障及热点不均衡问题。
应用场景:
多副本高吞吐场景
小部分Worker计算资源使用率很高,其他Worker很低,有可能是查询不均导致的,此时增加Shard的副本数量,使更多的Worker上有Shard的副本,有效提高资源利用率和QPS。
多副本高可用场景
因为单Shard Failover时导致查询不可用情况,增加副本数量后,某个worker发生故障时,由于仍存在完整的Shard副本,实例可以继续。
结合DataWorks增强数据同步、血缘、地图、传输加密等能力
功能说明:
Hologres与DataWorks深度集成,在过去的MySQL、Oracle、PolarDB、SQLServer等数据源的基础上,V2.1版本新增支持ClickHouse整库全量、ADB整库同步、Kafka实时同步到Hologres。同时在DataWorks中可以采集Hologres元数据,查看Hologres表血缘和字段血缘信息。
更多完整功能列表请查看Hologres V2.1功能发布记录
向作者提问







